
Page 189 - Kaleidoscope Academic Conference Proceedings 2020
P. 189
BSR: A BALANCED FRAMEWORK FOR SINGLE IMAGE SUPER RESOLUTION
3
4
4
4
1,2
4
1,2
Dehui Kong , Fang Zhu , Yang Wei , Song Jianjun , Zhu Tongtong , Bengang Lou , Ke Xu
1 State Key Laboratory of Mobile Network and Mobile Multimedia Technology, China
2 ZTE Microelectronics Research Institute, China
3 ZTE Corporation, China
4 Sanechips, China
ABSTRACT learning-based [4]. The former two mainly include bilinear
or Lanczos interpolation and wavelet-based schemes.
The reconstruction effect of single image super resolution Learning-based methods, especially those deep
(SISR) has been greatly improved over the traditional convolutional neural networks, gain much attention for SR
statistic and feature-based methods since the wide applications since the introduction of pioneer work SRCNN
application of deep convolutional neural networks (DCNNs). in [5] due to their extraordinary performance in both peak
Most recent studies mainly focused on the complexity of the signal-to-noise ratio (PSNR) and perceptual quality as
neural network models and the stability of the training compared with non-deep-learning based methods.
process without paying much attention to imbalance
problems in the fields of super resolution. In this paper, we A typical DCNN for SR usually has three function blocks,
study three imbalance effects: sample imbalance, feature feature extraction, feature mapping, and HR reconstruction,
imbalance, and object function imbalance. A novel respectively. Most state-of-the-art methods focus on the
framework, which is called Balanced Super Resolution feature mapping stage which should maximize the DCNN
(BSR), is thus proposed to tackle these issues. Specifically, performance on non-linear mapping, and thus deeper
we propose a random filter sampling algorithm to form networks are more preferable in literature [6], [7], [8], [9]. In
balanced training sets during batch training. Meanwhile, a addition, skip connection, [10] and [11], has become a useful
feature mapping group, which is a kind of residual structure, network structure in DCNN for SR which helps to improve
is introduced to forward various groups of low-level training stability and attention on the underlying lower level
information to high-level. A light spatial attention characteristics [12].
mechanism is also proposed to improve the effectiveness of
residual features. Furthermore, we study the object functions
in traditional SISR networks and deploy a hybrid L1/L2/Lp
structure that favors visually-stable SR output. The proposed
design achieves persistently better image quality than state-
of-the-art DCNN methods in both subjective and objective
measurements.
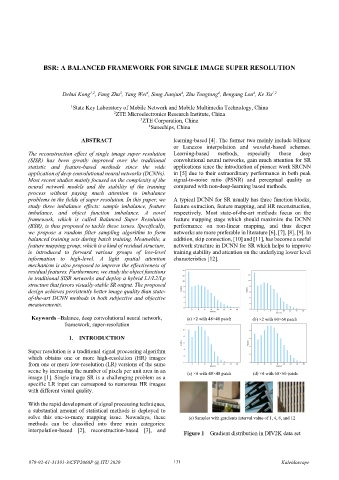
Keywords –Balance, deep convolutional neural network, (a) ×2 with 48×48 patch (b) ×2 with 60×60 patch
framework, super-resolution
1. INTRODUCTION
Super resolution is a traditional signal processing algorithm
which obtains one or more high-resolution (HR) images
from one or more low-resolution (LR) versions of the same
scene by increasing the number of pixels per unit area in an (c) ×4 with 48×48 patch (d) ×4 with 60×60 patch
image [1]. Single image SR is a challenging problem as a
specific LR input can correspond to numerous HR images
with different visual quality.
With the rapid development of signal processing techniques,
a substantial amount of statistical methods is deployed to
solve this one-to-many mapping issue. Nowadays, these (e) Samples with gradients interval value of 1, 4, 8, and 12
methods can be classified into three main categories:
interpolation-based [2], reconstruction-based [3], and Figure 1 – Gradient distribution in DIV2K data set
978-92-61-31391-3/CFP2068P @ ITU 2020 – 131 – Kaleidoscope