
Page 56 - ITU Journal Future and evolving technologies Volume 2 (2021), Issue 4 – AI and machine learning solutions in 5G and future networks
P. 56
ITU Journal on Future and Evolving Technologies, Volume 2 (2021), Issue 4
Table 1 – Comparison of the proposed method(MAN‑keypoint and MAN‑optical) with other previous works for GRID data set
Method SSIM↑ PSNR↑ CPBD↑ WER↓ ACD‑C↓ ACD‑E↓ blinks/sec LMD↓
FOMM[80] 0.833 26.72 0.214 38.21 0.004 0.088 0.56 0.718
OneShotA2V[4] 0.881 28.571 0.262 27.5 0.005 0.09 0.15 0.91
RSDGAN[42] 0.818 27.100 0.268 23.1 ‑ 1.47x10 −4 0.39 ‑
Speech2Vid[39] 0.720 22.662 0.255 58.2 0.007 1.48x10 −4 ‑ ‑
ATVGnet[48] 0.83 32.15 ‑ ‑ ‑ ‑ ‑ 1.29
X2face[43] 0.80 29.39 ‑ ‑ ‑ ‑ ‑ 1.48
CascadedGAN[46] 0.81 27.1 0.26 23.1 ‑ 1.47x10 −4 0.45 ‑
MAN‑optical 0.908 29.78 0.272 23.7 0.005 1.41x10 ‑4 0.45 0.77
MAN‑keypoint 0.887 29.01 0.269 25.2 0.006 1.41x10 −4 0.48 0.80
Table 2 – Comparison of the proposed method(MAN‑keypoint and MAN‑optical) with other previous works for CREMA‑D data set
Method SSIM↑ PSNR↑ CPBD↑ WER↓ ACD‑C↓ ACD‑E↓ blinks/sec LMD↓
FOMM[80] 0.654 20.74 0.186 NA 0.007 0.12 ‑ 1.041
OneShotA2V[4] 0.773 24.057 0.184 NA 0.006 0.96 ‑ 0.632
RSDGAN[42] 0.700 23.565 0.216 NA ‑ 1.40x10 ‑4 ‑ ‑
Speech2Vid[39] 0.700 22.190 0.217 NA 0.008 1.73x10 ‑4 ‑ ‑
MAN‑optical 0.826 27.723 0.224 NA 0.004 1.62x10 −4 ‑ 0.592
MAN‑keypoint 0.841 28.01 0.228 NA 0.003 1.38x10 ‑4 ‑ 0.51
Table 3 – Comparison of the proposed method(MAN‑keypoint and MAN‑optical) with other previous works for GRID Lombard data set
Method SSIM↑ PSNR↑ CPBD↑ WER↓ ACD‑C↓ ACD‑E↓ blinks/sec LMD↓
FOMM[80] 0.804 22.97 0.381 NA 0.003 0.078 0.37 1.09
OneShotA2V[4] 0.922 28.978 0.453 NA 0.002 0.064 0.1 0.61
Speech2Vid[39] 0.782 26.784 0.406 NA 0.004 0.069 ‑ 0.581
MAN‑optical 0.895 26.94 0.43 NA 0.001 0.048 0.21 0.588
MAN‑keypoint 0.931 29.62 0.492 NA 0.001 0.046 0.31 textbf0.563
Table 4 – Comparison of the proposed method(MAN‑keypoint and MAN‑optical) with other previous works for VOXCELEB2 data set
Method SSIM↑ PSNR↑ CPBD↑ WER↓ ACD‑C↓ ACD‑E↓ blinks/sec LMD↓
OneShotA2V[4] 0.698 20.921 0.103 NA 0.011 0.096 0.05 0.72
MAN‑optical 0.714 21.94 0.118 NA 0.008 0.067 0.21 0.65
MAN‑keypoint 0.732 22.41 0.126 NA 0.004 0.058 0.28 0.47
previous work [52] where the proposed model shows
Table 5 – Average QoE on proposed method better image reconstruction and lip synchronization.
3
The generated videos are given at .
Method QoE ↑
MAN‑optical(GRID) 1.232
MAN‑keypoint(GRID) 1.074
MAN‑optical(GRID‑Lombard) 0.624
MAN‑keypoint(GRID‑Lombard) 1.20
MAN‑optical(CREMA‑D) 0.797
MAN‑keypoint(CREMA‑D) 0.860
MAN‑optical(VoxCeleb2) ‑0.595
MAN‑keypoint(VoxCeleb2) ‑0.472
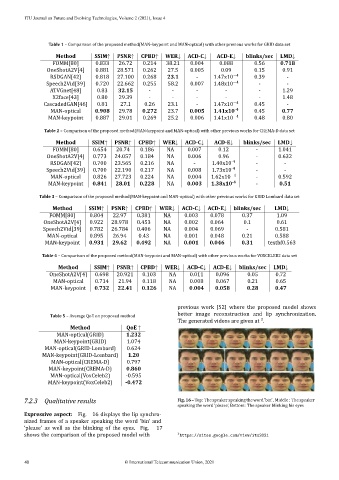
7.2.3 Qualitative results Fig. 16 – Top: The speaker speaking the word ’bin’ , Middle : The speaker
speaking the word ’please’, Bottom: The speaker blinking his eyes
Expressive aspect: Fig. 16 displays the lip synchro‑
nized frames of a speaker speaking the word ’bin’ and
’please’ as well as the blinking of the eyes. Fig. 17
shows the comparison of the proposed model with 3 https://sites.google.com/view/itu2021
40 © International Telecommunication Union, 2021