
Page 329 - Kaleidoscope Academic Conference Proceedings 2024
P. 329
Innovation and Digital Transformation for a Sustainable World
10 7 efficiency, thus increasing the offloading capability and the
2.5
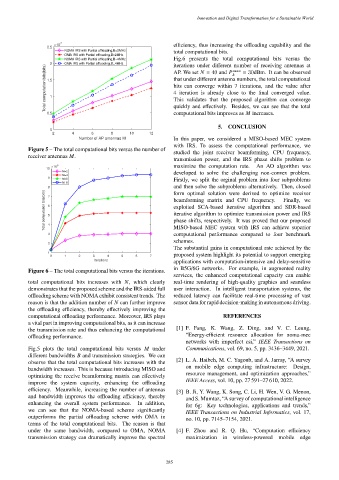
NOMA IRS with Partial offloading,B=2MHz total computational bits.
OMA IRS with Partial offloading,B=2MHz
NOMA IRS with Partial offloading,B=4MHz Fig.6 presents the total computational bits versus the
2 OMA IRS with Partial offloading,B=4MHz iterations under different number of receiving antennas at
Total computation bits(bits) 1.5 1 that under different antenna numbers, the total computational
max
= 30dBm. It can be observed
AP. We set = 40 and
bits can converge within 7 iterations, and the value after
4 iteration is already close to the final converged value.
This validates that the proposed algorithm can converge
computational bits improves as increases.
0.5 quickly and effectively. Besides, we can see that the total
5. CONCLUSION
0
2 4 6 8 10 12
Number of AP antennas M In this paper, we considered a MISO-based MEC system
with IRS. To assess the computational performance, we
Figure 5 – The total computational bits versus the number of
studied the joint receiver beamforming, CPU frequency,
receiver antennas .
transmission power, and the IRS phase shifts problem to
6
10 maximize the computation rate. An AO algorithm was
10
M=2 developed to solve the challenging non-convex problem.
M=4
9 M=6 Firstly, we split the orginal problem into four subproblems
M=8
8 7 and then solve the subproblems alternatively. Then, closed
Total computation bits(bits) 6 5 beamforming matrix and CPU frequency. Finally, we
form optimal solution were derived to optimize receiver
exploited SCA-based iterative algorithm and SDR-based
iterative algorithm to optimize transmission power and IRS
phase shifts, respectively. It was proved that our proposed
computational performance compared to four benchmark
3 4 MISO-based MEC system with IRS can achieve superior
schemes.
2
The substantial gains in computational rate achieved by the
1
0 1 2 3 4 5 6 7 proposed system highlight its potential to support emerging
Iterations
applications with computation-intensive and delay-sensitive
in B5G/6G networks. For example, in augmented reality
Figure 6 – The total computational bits versus the iterations.
services, the enhanced computational capacity can enable
total computational bits increases with , which clearly real-time rendering of high-quality graphics and seamless
demonstrates that the proposed scheme and the IRS-aided full user interaction. In intelligent transportation systems, the
offloading scheme with NOMA exhibit consistent trends. The reduced latency can facilitate real-time processing of vast
reason is that the addition number of can further improve sensor data for rapid decision-making in autonomous driving.
the offloading efficiency, thereby effectively improving the
computational offloading performance. Moreover, IRS plays REFERENCES
a vital part in improving computational bits, as it can increase
the transmission rate and thus enhancing the computational [1] F. Fang, K. Wang, Z. Ding, and V. C. Leung,
“Energy-efficient resource allocation for noma-mec
offloading performance.
networks with imperfect csi,” IEEE Transactions on
Fig.5 plots the total computational bits versus under Communications, vol. 69, no. 5, pp. 3436–3449, 2021.
different bandwidths and transmission strategies. We can
[2] L. A. Haibeh, M. C. Yagoub, and A. Jarray, “A survey
observe that the total computational bits increases with the
on mobile edge computing infrastructure: Design,
bandwidth increases. This is because introducing MISO and
resource management, and optimization approaches,”
optimizing the receive beamforming matrix can effectively
IEEE Access, vol. 10, pp. 27 591–27 610, 2022.
improve the system capacity, enhancing the offloading
efficiency. Meanwhile, increasing the number of antennas
[3] B. Ji, Y. Wang, K. Song, C. Li, H. Wen, V. G. Menon,
and bandwidth improves the offloading efficiency, thereby
and S. Mumtaz, “A survey of computational intelligence
enhancing the overall system performance. In addition,
for 6g: Key technologies, applications and trends,”
we can see that the NOMA-based scheme significantly
IEEE Transactions on Industrial Informatics, vol. 17,
outperforms the partial offloading scheme with OMA in
no. 10, pp. 7145–7154, 2021.
terms of the total computational bits. The reason is that
under the same bandwidth, compared to OMA, NOMA [4] F. Zhou and R. Q. Hu, “Computation efficiency
transmission strategy can dramatically improve the spectral maximization in wireless-powered mobile edge
– 285 –