
Page 219 - Kaleidoscope Academic Conference Proceedings 2024
P. 219
Innovation and Digital Transformation for a Sustainable World
indicates that the responses generated by the model are highly
similar to the reference responses in the dataset, suggesting
that it can produce outputs that closely match the expected
language and content. The model achieved a low perplexity
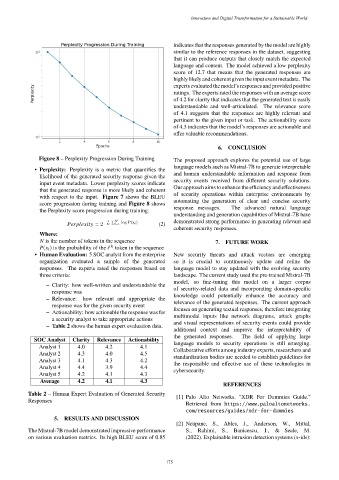
score of 12.7 that means that the generated responses are
highly likely and coherent given the input event metadata. The
experts evaluated the model’s responses and provided positive
ratings. The experts rated the responses with an average score
of 4.2 for clarity that indicates that the generated text is easily
understandable and well-articulated. The relevance score
of 4.1 suggests that the responses are highly relevant and
pertinent to the given input or task. The actionability score
of 4.3 indicates that the model’s responses are actionable and
offer valuable recommendations.
6. CONCLUSION
Figure 8 – Perplexity Progression During Training The proposed approach explores the potential use of large
• Perplexity: Perplexity is a metric that quantifies the language models such as Mistral-7B to generate interpretable
likelihood of the generated security response given the and human understandable information and response from
input event metadata. Lower perplexity scores indicate security events received from different security solutions.
that the generated response is more likely and coherent Our approach aims to enhance the efficiency and effectiveness
with respect to the input. Figure 7 shows the BLEU of security operations within enterprise environments by
score progression during training and Figure 8 shows automating the generation of clear and concise security
the Perplexity score progression during training. response messages. The advanced natural language
understanding and generation capabilities of Mistral-7B have
N
Perplexity = 2 − 1 N Í i=1 log P(x i ) (2) demonstrated strong performance in generating relevant and
coherent security responses.
Where:
N is the number of tokens in the sequence 7. FUTURE WORK
P(x i ) is the probability of the i th token in the sequence
• Human Evaluation: 5 SOC analyst from the enterprise New security threats and attack vectors are emerging
organization evaluated a sample of the generated so it is crucial to continuously update and refine the
responses. The experts rated the responses based on language model to stay updated with the evolving security
three criteria: landscape. The current study used the pre-trained Mistral-7B
– Clarity: how well-written and understandable the model, so fine-tuning this model on a larger corpus
of security-related data and incorporating domain-specific
response was
– Relevance: how relevant and appropriate the knowledge could potentially enhance the accuracy and
relevance of the generated responses. The current approach
response was for the given security event
– Actionability: how actionable the response was for focuses on generating textual responses, therefore integrating
multimodal inputs like network diagrams, attack graphs
a security analyst to take appropriate actions
– Table 2 shows the human expert evaluation data. and visual representations of security events could provide
additional context and improve the interpretability of
the generated responses. The field of applying large
SOC Analyst Clarity Relevance Actionability language models to security operations is still emerging.
Analyst 1 4.0 4.2 4.1 Collaborative efforts among industry experts, researchers and
Analyst 2 4.3 4.0 4.5 standardization bodies are needed to establish guidelines for
Analyst 3 4.1 4.3 4.2 the responsible and effective use of these technologies in
Analyst 4 4.4 3.9 4.4 cybersecurity.
Analyst 5 4.2 4.1 4.3
Average 4.2 4.1 4.3
REFERENCES
Table 2 – Human Expert Evaluation of Generated Security [1] Palo Alto Networks. "XDR For Dummies Guide."
Responses
Retrieved from https://www.paloaltonetworks.
com/resources/guides/xdr-for-dummies
5. RESULTS AND DISCUSSION
[2] Neupane, S., Ables, J., Anderson, W., Mittal,
The Mistral-7B model demonstrated impressive performance S., Rahimi, S., Banicescu, I., & Seale, M.
on various evaluation metrics. Its high BLEU score of 0.85 (2022). Explainable intrusion detection systems (x-ids):
– 175 –