
Page 217 - Kaleidoscope Academic Conference Proceedings 2024
P. 217
Innovation and Digital Transformation for a Sustainable World
expert networks, enabling superior performance while
maintaining computational efficiency.
M − 7 = SMoE(N experts , N params , f routing , f experts )
Where:
M − 7 is Mistral-7B model
SMoE is the Sparse Mixture-of-Experts model
N experts is the number of expert models
N params ≈ 7 × 10 is the total number of parameters
9
f routing is the routing function assigns input to experts
f experts are the expert models that process the inputs
• Item Model Size and Capabilities: Mistral-7B is
a large-scale language model capable of capturing
intricate patterns and relationships within natural
language data. Its substantial parameter count endows it
with remarkable linguistic understanding and generation
abilities, making it well-suited for a wide range of
natural language processing tasks like text generation,
summarization, question answering, and language
translation.
• Multilingual Support: One of Mistral-7B’s notable
features is its multilingual support. The model has
been trained on data from multiple languages, like
English, French, Italian, German, and Spanish. This
multilingual capability enables the model to understand
and generate text in various languages, facilitating
cross-lingual applications and enhancing its utility in
diverse linguistic contexts.
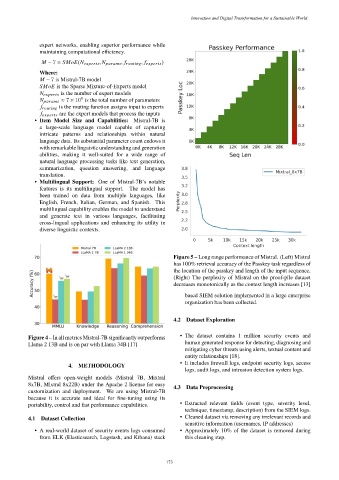
Figure 5 – Long range performance of Mistral. (Left) Mistral
has 100% retrieval accuracy of the Passkey task regardless of
the location of the passkey and length of the input sequence.
(Right) The perplexity of Mistral on the proof-pile dataset
decreases monotonically as the context length increases [13]
based SIEM solution implemented in a large enterprise
organization has been collected.
4.2 Dataset Exploration
Figure 4 – In all metrics Mistral-7B significantly outperforms • The dataset contains 1 million security events and
Llama 2 13B and is on par with Llama 34B [17] human generated response for detecting, diagnosing and
mitigating cyber threats using alerts, textual content and
entity relationships [18].
• It includes firewall logs, endpoint security logs, access
4. METHODOLOGY
logs, audit logs, and intrusion detection system logs.
Mistral offers open-weight models (Mistral 7B, Mixtral
8x7B, Mixtral 8x22B) under the Apache 2 license for easy
customization and deployment. We are using Mistral-7B 4.3 Data Preprocessing
because it is accurate and ideal for fine-tuning using its
portability, control and fast performance capabilities. • Extracted relevant fields (event type, severity level,
technique, timestamp, description) from the SIEM logs.
• Cleaned dataset via removing any irrelevant records and
4.1 Dataset Collection
sensitive information (usernames, IP addresses)
• A real-world dataset of security events logs consumed • Approximately 10% of the dataset is removed during
from ELK (Elasticsearch, Logstash, and Kibana) stack this cleaning step.
– 173 –