
Page 218 - Kaleidoscope Academic Conference Proceedings 2024
P. 218
2024 ITU Kaleidoscope Academic Conference
4.4 Data Normalization
• Tokenization: breaking down the description into tokens
• Lemmatization: Reduced words to their base form (e.g.,
"running" to "run") that helps to reduce the vocabulary
size and improve generalization.
• Stop-word removal: Removing commonly occurring
words (e.g., "the," "and," "is") that do not contribute
much to the meaning of the text.
4.5 Data Splitting
• Split the dataset into three subsets: training, validation,
and test sets. The training set (70% of the data) is used
to fine-tune the Mistral-7B model.
• The validation set (15% of the data) is used to monitor
the model’s performance during training and tune
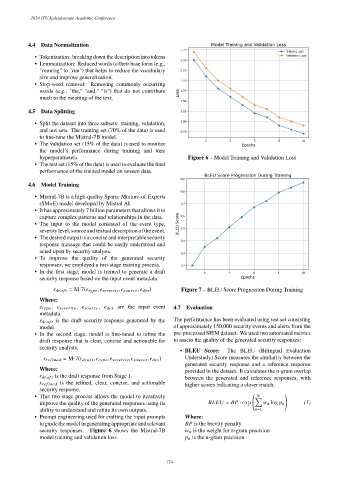
hyperparameters. Figure 6 – Model Training and Validation Loss
• The test set (15% of the data) is used to evaluate the final
performance of the trained model on unseen data.
4.6 Model Training
• Mistral-7B is a high-quality Sparse Mixture-of-Experts
(SMoE) model developed by Mistral AI.
• It has approximately 7 billion parameters that allows it to
capture complex patterns and relationships in the data.
• The input to the model consisted of the event type,
severity level, source and textual description of the event.
• The desired output is a concise and interpretable security
response message that could be easily understood and
acted upon by security analysts.
• To improve the quality of the generated security
responses, we employed a two-stage training process.
• In the first stage, model is trained to generate a draft
security response based on the input event metadata.
r draf t = M-7(e type ,e severity ,e source ,e des ) Figure 7 – BLEU Score Progression During Training
Where:
e type , e severity , e source , e des are the input event 4.7 Evaluation
metadata.
r draf t is the draft security response generated by the The performance has been evaluated using test set consisting
model. of approximately 150,000 security events and alerts from the
• In the second stage, model is fine-tuned to refine the pre-processed SIEM dataset. We used two automated metrics
draft response that is clear, concise and actionable for to assess the quality of the generated security responses:
security analysts.
• BLEU Score: The BLEU (Bilingual Evaluation
Understudy) Score measures the similarity between the
r ref ined = M-7(r draf t ,e type ,e severity ,e source ,e des )
generated security response and a reference response
Where: provided in the dataset. It calculates the n-gram overlap
r draf t is the draft response from Stage 1. between the generated and reference responses, with
r ref ined is the refined, clear, concise, and actionable higher scores indicating a closer match.
security response.
• This two-stage process allows the model to iteratively N Õ !
improve the quality of the generated responses using its BLEU = BP · exp w n log p n (1)
ability to understand and refine its own outputs. n=1
• Prompt engineering used for crafting the input prompts Where:
to guide the model in generating appropriate and relevant BP is the brevity penalty
security responses. Figure 6 shows the Mistral-7B w n is the weight for n-gram precision
model training and validation loss. p n is the n-gram precision
– 174 –