
Page 211 - Kaleidoscope Academic Conference Proceedings 2024
P. 211
Innovation and Digital Transformation for a Sustainable World
in Proceedings of the IEEE/CVF conference on
computer vision and pattern recognition, 2019, pp.
2327–2336.
[5] M. U. Lokumarambage, V. S. S. Gowrisetty, H. Rezaei,
T. Sivalingam, N. Rajatheva, and A. Fernando,
“Wireless end-to-end image transmission system using
semantic communications,” IEEE Access, 2023.
[6] J. Li, D. Li, C. Xiong, and S. Hoi, “Blip:
Bootstrapping language-image pre-training for unified
vision-language understanding and generation,” in
International conference on machine learning. PMLR,
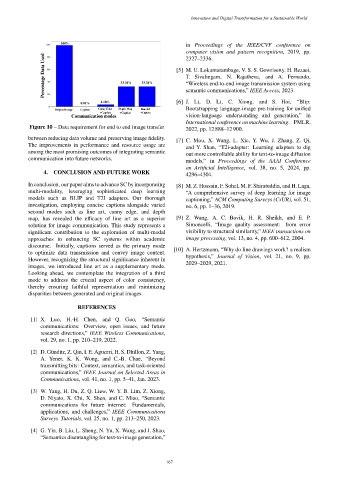
Figure 10 – Data requirement for end to end image transfer 2022, pp. 12 888–12 900.
between reducing data volume and preserving image fidelity.
[7] C. Mou, X. Wang, L. Xie, Y. Wu, J. Zhang, Z. Qi,
The improvements in performance and resource usage are
and Y. Shan, “T2i-adapter: Learning adapters to dig
among the most promising outcomes of integrating semantic
out more controllable ability for text-to-image diffusion
communication into future networks.
models,” in Proceedings of the AAAI Conference
on Artificial Intelligence, vol. 38, no. 5, 2024, pp.
4. CONCLUSION AND FUTURE WORK
4296–4304.
In conclusion, our paper aims to advance SC by incorporating [8] M. Z. Hossain, F. Sohel, M. F. Shiratuddin, and H. Laga,
multi-modality, leveraging sophisticated deep learning “A comprehensive survey of deep learning for image
models such as BLIP and T2I adapters. Our thorough captioning,” ACM Computing Surveys (CsUR), vol. 51,
investigation, employing concise captions alongside varied no. 6, pp. 1–36, 2019.
second modes such as line art, canny edge, and depth
map, has revealed the efficacy of line art as a superior [9] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P.
solution for image communication. This study represents a Simoncelli, “Image quality assessment: from error
significant contribution to the exploration of multi-modal visibility to structural similarity,” IEEE transactions on
approaches in enhancing SC systems within academic image processing, vol. 13, no. 4, pp. 600–612, 2004.
discourse. Initially, captions served as the primary mode
[10] A. Hertzmann, “Why do line drawings work? a realism
to optimize data transmission and convey image content.
hypothesis,” Journal of Vision, vol. 21, no. 9, pp.
However, recognizing the structural significance inherent in
2029–2029, 2021.
images, we introduced line art as a supplementary mode.
Looking ahead, we contemplate the integration of a third
mode to address the crucial aspect of color consistency,
thereby ensuring faithful representation and minimizing
disparities between generated and original images.
REFERENCES
[1] X. Luo, H.-H. Chen, and Q. Guo, “Semantic
communications: Overview, open issues, and future
research directions,” IEEE Wireless Communications,
vol. 29, no. 1, pp. 210–219, 2022.
[2] D. Gündüz, Z. Qin, I. E. Aguerri, H. S. Dhillon, Z. Yang,
A. Yener, K. K. Wong, and C.-B. Chae, “Beyond
transmitting bits: Context, semantics, and task-oriented
communications,” IEEE Journal on Selected Areas in
Communications, vol. 41, no. 1, pp. 5–41, Jan. 2023.
[3] W. Yang, H. Du, Z. Q. Liew, W. Y. B. Lim, Z. Xiong,
D. Niyato, X. Chi, X. Shen, and C. Miao, “Semantic
communications for future internet: Fundamentals,
applications, and challenges,” IEEE Communications
Surveys Tutorials, vol. 25, no. 1, pp. 213–250, 2023.
[4] G. Yin, B. Liu, L. Sheng, N. Yu, X. Wang, and J. Shao,
“Semantics disentangling for text-to-image generation,”
– 167 –