
Page 187 - Kaleidoscope Academic Conference Proceedings 2024
P. 187
Innovation and Digital Transformation for a Sustainable World
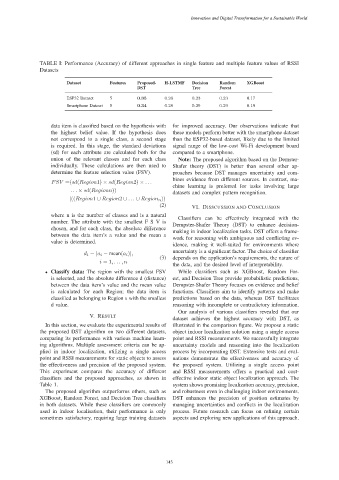
TABLE I: Performance (Accuracy) of different approaches in single feature and multiple feature values of RSSI
Datasets
Dataset Features Proposed- H-LSTMF Decision Random XGBoost
DST Tree Forest
ESP32 Dataset 5 0.35 0.26 0.23 0.23 0.17
Smartphone Dataset 5 0.34 0.28 0.29 0.29 0.19
data item is classified based on the hypothesis with for improved accuracy. Our observations indicate that
the highest belief value. If the hypothesis does these models perform better with the smartphone dataset
not correspond to a single class, a second stage than the ESP32-based dataset, likely due to the limited
is required. In this stage, the standard deviations signal range of the low-cost Wi-Fi development board
(sd) for each attribute are calculated both for the compared to a smartphone.
union of the relevant classes and for each class Note: The proposed algorithm based on the Demster-
individually. These calculations are then used to Shafer theory (DST) is better than several other ap-
determine the feature selection value (FSV). proaches because DST manages uncertainty and com-
bines evidence from different sources. In contrast, ma-
FSV =(sd(Region1) × sd(Region2) × ...
chine learning is preferred for tasks involving large
... × sd(Regionn))
datasets and complex pattern recognition.
|((Region1 ∪ Region2 ∪ ... ∪ Region n ))
(2)
VI. DISSCUSSION AND CONCLUSION
where n is the number of classes and is a natural
Classifiers can be effectively integrated with the
number. The attribute with the smallest F S V is
Dempster-Shafer Theory (DST) to enhance decision-
chosen, and for each class, the absolute difference making in indoor localization tasks. DST offers a frame-
between the data item’s a value and the mean a
work for reasoning with ambiguous and conflicting ev-
value is determined.
idence, making it well-suited for environments where
d i = |a i − mean(a i )|, uncertainty is a significant factor. The choice of classifier
(3) depends on the application’s requirements, the nature of
i =1,...,n
the data, and the desired level of interpretability.
• Classify data: The region with the smallest FSV While classifiers such as XGBoost, Random For-
is selected, and the absolute difference d (distance) est, and Decision Tree provide probabilistic predictions,
between the data item’s value and the mean value Dempster-Shafer Theory focuses on evidence and belief
is calculated for each Region; the data item is functions. Classifiers aim to identify patterns and make
classified as belonging to Region x with the smallest predictions based on the data, whereas DST facilitates
d value. reasoning with incomplete or contradictory information.
Our analysis of various classifiers revealed that our
V. RESULT
dataset achieves the highest accuracy with DST, as
In this section, we evaluate the experimental results of illustrated in the comparison figure. We propose a static
the proposed DST algorithm on two different datasets, object indoor localization solution using a single access
comparing its performance with various machine learn- point and RSSI measurements. We successfully integrate
ing algorithms. Multiple assessment criteria can be ap- uncertainty models and reasoning into the localization
plied in indoor localization, utilizing a single access process by incorporating DST. Extensive tests and eval-
point and RSSI measurements for static objects to assess uations demonstrate the effectiveness and accuracy of
the effectiveness and precision of the proposed system. the proposed system. Utilizing a single access point
This experiment compares the accuracy of different and RSSI measurements offers a practical and cost-
classifiers and the proposed approaches, as shown in effective indoor static object localization approach. The
Table 1. system shows promising localization accuracy, precision,
The proposed algorithm outperforms others, such as and robustness even in challenging indoor environments.
XGBoost, Random Forest, and Decision Tree classifiers DST enhances the precision of position estimates by
in both datasets. While these classifiers are commonly managing uncertainties and conflicts in the localization
used in indoor localisation, their performance is only process. Future research can focus on refining certain
sometimes satisfactory, requiring large training datasets aspects and exploring new applications of this approach.
– 143 –