
Page 122 - Kaleidoscope Academic Conference Proceedings 2024
P. 122
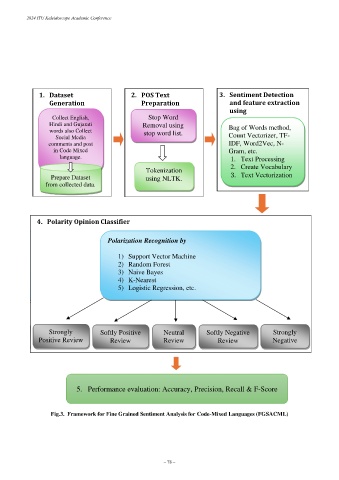
2024 ITU Kaleidoscope Academic Conference
1. Dataset 2. POS Text 3. Sentiment Detection
Generation Preparation and feature extraction
using
Collect English, Stop Word
Hindi and Gujarati Removal using
words also Collect stop word list. Bag of Words method,
Social Media Count Vectorizer, TF-
comments and post IDF, Word2Vec, N-
in Code Mixed Gram, etc.
language. 1. Text Processing
2. Create Vocabulary
Tokenization
Prepare Dataset using NLTK. 3. Text Vectorization
from collected data.
4. Polarity Opinion Classifier
Polarization Recognition by
1) Support Vector Machine
2) Random Forest
3) Naive Bayes
4) K-Nearest
5) Logistic Regression, etc.
Strongly Softly Positive Neutral Softly Negative Strongly
Positive Review Review Review Review Negative
5. Performance evaluation: Accuracy, Precision, Recall & F-Score
sda
Fig.3. Framework for Fine Grained Sentiment Analysis for Code-Mixed Languages (FGSACML)
– 78 –