
Page 121 - Kaleidoscope Academic Conference Proceedings 2024
P. 121
Innovation and Digital Transformation for a Sustainable World
3. LITERATURE REVIEW Table 2 provides a comprehensive overview of sentiment
analysis studies. IMDB reviews were analyzed, achieving
Table 1 – Analysis of SA methods for Indian Languages accuracies of 81.0% to 82.9% with different supervised
learning approaches [30]. Focused on movie and car brand
Classification Level of
Ref. Language reviews achieving 87.2% accuracy [31]. Obtained 90.25%
Method Used Accuracy accuracy on blog data using Naive Bayes Multinomial [32].
[17] SVM 78.14 Reached 66% accuracy on reviews with a lexicon-based
approach [33]. Achieved 80% accuracy on data mining based
[18] HINDI Naïve Bayes 87.1 on customer review [34]. Utilized neural networks for 95%
[19] Lexicon Based 70% accuracy for data mining on the Web [35]. Lastly, a survey
[36] achieved 82.30% accuracy using sentiment lexicon and
Guj-Sento Word
Linear SVM on CNET software and IMDB reviews.
[20] Net, Bag-of- 52.27% Sentiment analysis using text analytics is one of the greatest
Gujarati
Word, Word Net methods for conducting market research. These illuminating
statistics can help brands set themselves out from the
[21] SVM 92%
competition. Businesses are starting to adopt AI-powered
[22] Bengali SVM 98.7% sentiment analysis as a vital tool [40].
[23] Naïve Bayes Not Available
Punjabi 4. FRAMEWORK OVERVIEW
[24] Decision Tree Not Available
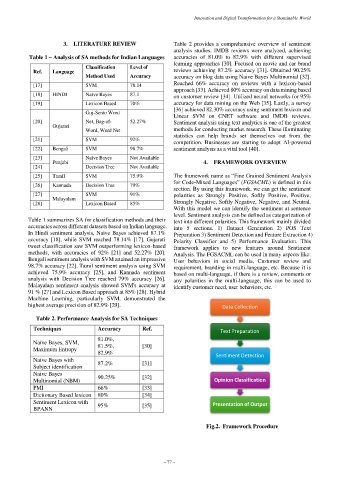
[25] Tamil SVM 75.9% The framework name as “Fine Grained Sentiment Analysis
for Code-Mixed Languages” (FGSACML) is defined in this
[26] Kannada Decision Tree 79%
section. By using this framework, we can get the sentiment
[27] SVM 91% polarities as Strongly Positive, Softly Positive, Positive,
Malayalam
[28] Lexicon Based 85% Strongly Negative, Softly Negative, Negative, and Neutral.
With this model we can identify the sentiment at sentence
level. Sentiment analysis can be defined as categorization of
Table 1 summarizes SA for classification methods and their text into different polarities. This framework mainly divided
accuracies across different datasets based on Indian language. into 5 sections. 1) Dataset Generation 2) POS Text
In Hindi sentiment analysis, Naive Bayes achieved 87.1% Preparation 3) Sentiment Detection and Feature Extraction 4)
accuracy [18], while SVM reached 78.14% [17]. Gujarati Polarity Classifier and 5) Performance Evaluation. This
tweet classification saw SVM outperforming lexicon-based framework applies to new features around Sentiment
methods, with accuracies of 92% [21] and 52.27% [20]. Analysis. The FGSACML can be used in many aspects like:
Bengali sentiment analysis with SVM attained an impressive User behaviors in social media, Customer review and
98.7% accuracy [22]. Tamil sentiment analysis using SVM requirement, branding in multi-language, etc. Because it is
achieved 75.9% accuracy [25], and Kannada sentiment based on multi-language, if there is a review, comments or
analysis with Decision Tree reached 79% accuracy [26]. any polarities in the multi-language, this can be used to
Malayalam sentiment analysis showed SVM's accuracy at identify customer need, user behaviors, etc.
91 % [27] and Lexicon Based approach at 85% [28]. Hybrid
Machine Learning, particularly SVM, demonstrated the
highest average precision of 82.9% [29]. Data Collection
Table 2. Performance Analysis for SA Techniques
Techniques Accuracy Ref. Text Preparation
81.0%,
Naïve Bayes, SVM, 81.5%, [30]
Maximum Entropy
82.9% Sentiment Detection
Naive Bayes with 87.2% [31]
Subject identification
Naive Bayes 90.25% [32]
Multinomial (NBM) Opinion Classification
PMI 66% [33]
Dictionary Based lexicon 80% [34]
Sentiment Lexicon with 95% [35] Presentation of Output
BPANN
Fig.2. Framework Procedure
– 77 –