
Page 310 - Cloud computing: From paradigm to operation
P. 310
1 Framework and requirements for cloud computing
I.4 Guaranteed availability in the event of a disaster or large-scale failure
Table I.4 shows inter-cloud use case for guaranteed availability in the event of a disaster or large-scale
failure.
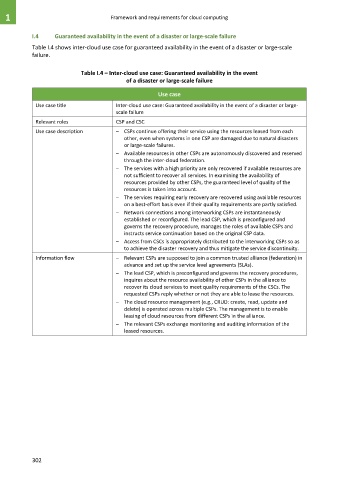
Table I.4 – Inter-cloud use case: Guaranteed availability in the event
of a disaster or large-scale failure
Use case
Use case title Inter-cloud use case: Guaranteed availability in the event of a disaster or large-
scale failure
Relevant roles CSP and CSC
Use case description – CSPs continue offering their service using the resources leased from each
other, even when systems in one CSP are damaged due to natural disasters
or large-scale failures.
– Available resources in other CSPs are autonomously discovered and reserved
through the inter-cloud federation.
– The services with a high priority are only recovered if available resources are
not sufficient to recover all services. In examining the availability of
resources provided by other CSPs, the guaranteed level of quality of the
resources is taken into account.
– The services requiring early recovery are recovered using available resources
on a best-effort basis even if their quality requirements are partly satisfied.
– Network connections among interworking CSPs are instantaneously
established or reconfigured. The lead CSP, which is preconfigured and
governs the recovery procedure, manages the roles of available CSPs and
instructs service continuation based on the original CSP data.
– Access from CSCs is appropriately distributed to the interworking CSPs so as
to achieve the disaster recovery and thus mitigate the service discontinuity.
Information flow – Relevant CSPs are supposed to join a common trusted alliance (federation) in
advance and set up the service level agreements (SLAs).
– The lead CSP, which is preconfigured and governs the recovery procedures,
inquires about the resource availability of other CSPs in the alliance to
recover its cloud services to meet quality requirements of the CSCs. The
requested CSPs reply whether or not they are able to lease the resources.
– The cloud resource management (e.g., CRUD: create, read, update and
delete) is operated across multiple CSPs. The management is to enable
leasing of cloud resources from different CSPs in the alliance.
– The relevant CSPs exchange monitoring and auditing information of the
leased resources.
302