
Page 126 - Proceedings of the 2018 ITU Kaleidoscope
P. 126
2018 ITU Kaleidoscope Academic Conference
Figure 1 – Learning model
such cases, another method must be employed in order to get
successful results.
1.3 Machine Learning
Machine Learning is one of the most active research areas
within Artificial Intelligence. It consists of constructing
learning systems that use a large amount of past data to infer
solutions for new problems. In other words, this is done
by analyzing a training dataset and using that information to
predict behaviour, values or make a decision upon new data. Figure 2 – Example of finding k near neighbours.
Supervised Machine Learning refers to learning algorithms
that extract specific features from the training dataset to
approximate the mapping function that relates an input
variable to an output variable. A common supervised learning
problem is a classification problem, where the output is a
category and the input variable should be classified. Two
supervised learning methods used as classifiers are support
vector machines (SVMs) and k-nearest neighbors (kNNs).
The learning model is composed of three elements as shown in
Fig. 1. A random variables generator that generates samples
l
x ∼ X ⊂ R of dimension l, feeds the supervisor and learner. (a) Boundary using 3 (b) Boundary using 7
Also, the learner needs to be filled with the output of the neighbours. neighbours.
supervisor y ∼ Y ⊂ R, to estimate ˆ y.
Figure 3 – Effect of choosing different k.
1.4 Feature extraction
can be chosen as close as needed. However, this could lead to
problems in the stability of the predictions, as shown in Fig.
The input data of a specific problem is usually too large to
3a and 3b.
be processed, and also redundant. In order to solve this,
The training phase of the algorithm consist of storing vectors
the input data can be turned into a reduced representation
in a multidimensional feature space, labeling them with
set of features. When the features are carefully chosen,
classes. These vectors are generated with the training
the representation has relevant data and gathers the desired
samples. Then, in the classification phase, an unlabeled
information. By this method, it is possible to perform
vector, is assigned to the class which is most frequent among
the desired task using reduced information, and make the
the k closest training samples to that point. Euclidean
algorithm more efficient.
distance is a commonly used distance metric for continuous
Generally a complex analysis of data with large number
variables.
of variables require a large amount of memory and
The choice of k impacts on the classification result.
computational power. Furthermore, too much information
Depending on the problem, and specially on the nature of the
may cause a classification algorithm to poorly generalize new
data, larger values of k can reduce the effect of the noise on the
samples by overfitting to the training samples. By using
classification, but it could cause wrong predictions between
feature extraction, these problems can be solved[11].
less distinct classes. Moreover, it is helpful to choose an odd
k if it is a binary classification problem in order to prevent
1.5 k-Nearest Neighbors
ties[9].
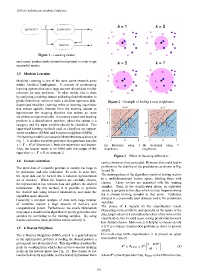
The k-Nearest Neighbors (kNN) search is a generalization For multi-class kNN classification, it is proved an upper
of the optimization problem of finding the closest point to a bound error rate of:
given point in a determined set. This algorithm classifies the ∗ ∗ 2 − MR ∗
point by counting from which class are the k-nearest training R ≤ R kN N ≤ R (4)
M − 1
points in the feature space (see Fig. 2). The classes do not
∗
need to be linearly separable, and the boundary between them where R is the Bayes error rate, R kN N is the kNN error rate,
– 110 –