
Page 109 - Kaleidoscope Academic Conference Proceedings 2024
P. 109
Innovation and Digital Transformation for a Sustainable World
[4] R. L. Smith and T. H. Lee, "Quantum Computing Gate
Emulation Using CMOS Oscillatory Cellular Neural
Networks," IEEE Transactions on Circuits and Systems
II: Express Briefs, doi: 10.1109/TCSII.2024.3397846.
[5] Betkaoui, Brahim, David B. Thomas, and Wayne
Luk. "Comparing performance and energy efficiency
of FPGAs and GPUs for high productivity computing."
2010 International Conference on Field-Programmable
Technology. IEEE, 2010.
[6] Asano, Shuichi, Tsutomu Maruyama, and Yoshiki
Yamaguchi. "Performance comparison of FPGA,
GPU, and CPU in image processing." 2009
international conference on field programmable logic
and applications. IEEE, 2009.
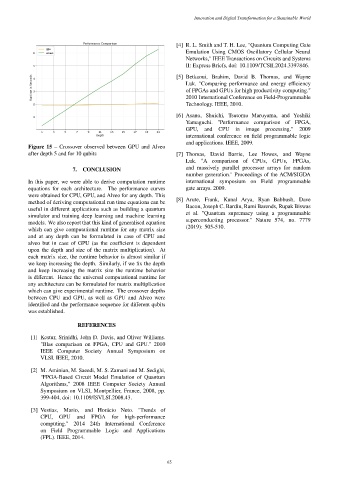
Figure 15 – Crossover observed between GPU and Alveo
after depth 5 and for 10 qubits [7] Thomas, David Barrie, Lee Howes, and Wayne
Luk. "A comparison of CPUs, GPUs, FPGAs,
7. CONCLUSION and massively parallel processor arrays for random
number generation." Proceedings of the ACM/SIGDA
In this paper, we were able to derive computation runtime international symposium on Field programmable
equations for each architecture. The performance curves gate arrays. 2009.
were obtained for CPU, GPU, and Alveo for any depth. This
[8] Arute, Frank, Kunal Arya, Ryan Babbush, Dave
method of deriving computational run time equations can be
Bacon, Joseph C. Bardin, Rami Barends, Rupak Biswas
useful in different applications such as building a quantum
et al. "Quantum supremacy using a programmable
simulator and training deep learning and machine learning
superconducting processor." Nature 574, no. 7779
models. We also report that this kind of generalised equation
(2019): 505-510.
which can give computational runtime for any matrix size
and at any depth can be formulated in case of CPU and
alveo but in case of GPU (as the coefficient is dependent
upon the depth and size of the matrix multiplication). At
each matrix size, the runtime behavior is almost similar if
we keep increasing the depth. Similarly, if we fix the depth
and keep increasing the matrix size the runtime behavior
is different. Hence the universal computational runtime for
any architecture can be formulated for matrix multiplication
which can give experimental runtime. The crossover depths
between CPU and GPU, as well as GPU and Alveo were
identified and the performance sequence for different qubits
was established.
REFERENCES
[1] Kestur, Srinidhi, John D. Davis, and Oliver Williams.
"Blas comparison on FPGA, CPU and GPU." 2010
IEEE Computer Society Annual Symposium on
VLSI. IEEE, 2010.
[2] M. Aminian, M. Saeedi, M. S. Zamani and M. Sedighi,
"FPGA-Based Circuit Model Emulation of Quantum
Algorithms," 2008 IEEE Computer Society Annual
Symposium on VLSI, Montpellier, France, 2008, pp.
399-404, doi: 10.1109/ISVLSI.2008.43.
[3] Vestias, Mario, and Horácio Neto. "Trends of
CPU, GPU and FPGA for high-performance
computing." 2014 24th International Conference
on Field Programmable Logic and Applications
(FPL). IEEE, 2014.
– 65 –