
Page 207 - Kaleidoscope Academic Conference Proceedings 2020
P. 207
Industry-driven digital transformation
true when the representation learning is applied to traffic
packets.
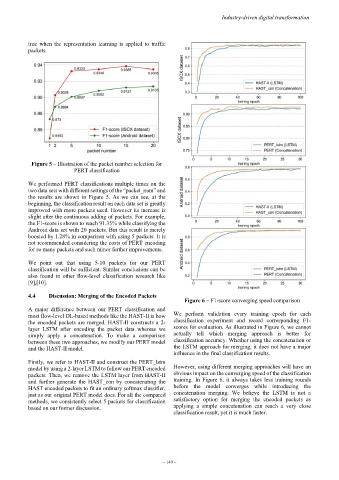
Figure 5 – Illustration of the packet number selection for
PERT classification
We performed PERT classifications multiple times on the
two data sets with different settings of the “packet_num” and
the results are shown in Figure 5. As we can see, at the
beginning, the classification result on each data set is greatly
improved with more packets used. However its increase is
slight after the continuous adding of packets. For example,
the F1-score is shown to reach 91.35% while classifying the
Android data set with 20 packets. But this result is merely
boosted by 1.28% in comparison with using 5 packets. It is
not recommended considering the costs of PERT encoding
for so many packets and such minor further improvements.
We point out that using 5-10 packets for our PERT
classification will be sufficient. Similar conclusions can be
also found in other flow-level classification research like
[9],[10].
4.4 Discussion: Merging of the Encoded Packets
Figure 6 – F1-score converging speed comparison
A major difference between our PERT classification and
most flow-level DL-based methods like the HAST-II is how We perform validation every training epoch for each
the encoded packets are merged. HAST-II constructs a 2- classification experiment and record corresponding F1-
layer LSTM after encoding the packet data whereas we scores for evaluation. As illustrated in Figure 6, we cannot
simply apply a concatenation. To make a comparison actually tell which merging approach is better for
between these two approaches, we modify our PERT model classification accuracy. Whether using the concatenation or
and the HAST-II model. the LSTM approach for merging, it does not have a major
influence in the final classification results.
Firstly, we refer to HAST-II and construct the PERT_lstm
model by using a 2-layer LSTM to follow our PERT encoded However, using different merging approaches will have an
packets. Then, we remove the LSTM layer from HAST-II obvious impact on the converging speed of the classification
and further generate the HAST_con by concatenating the training. In Figure 6, it always takes less training rounds
HAST encoded packets to fit an ordinary softmax classifier, before the model converges while introducing the
just as our original PERT model does. For all the compared concatenation merging. We believe the LSTM is not a
methods, we consistently select 5 packets for classification satisfactory option for merging the encoded packets as
based on our former discussion. applying a simple concatenation can reach a very close
classification result, yet it is much faster.
– 149 –