
Page 50 - Crowdsourcing AI and Machine Learning solutions for SDGs - ITU AI/ML Challenges 2024 Report
P. 50
Crowdsourcing AI and Machine Learning solutions for SDGs
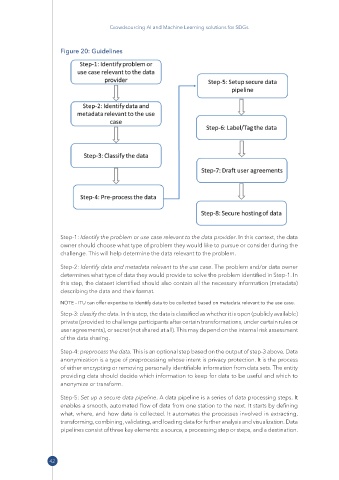
Figure 20: Guidelines
Step-1: Identify the problem or use case relevant to the data provider. In this context, the data
owner should choose what type of problem they would like to pursue or consider during the
challenge. This will help determine the data relevant to the problem.
Step-2: Identify data and metadata relevant to the use case. The problem and/or data owner
determines what type of data they would provide to solve the problem identified in Step-1. In
this step, the dataset identified should also contain all the necessary information (metadata)
describing the data and their format.
NOTE – ITU can offer expertise to identify data to be collected based on metadata relevant to the use case.
Step-3: classify the data. In this step, the data is classified as whether it is open (publicly available)
private (provided to challenge participants after certain transformations, under certain rules or
user agreements), or secret (not shared at all). This may depend on the internal risk assessment
of the data sharing.
Step-4: preprocess the data. This is an optional step based on the output of step-3 above. Data
anonymization is a type of preprocessing whose intent is privacy protection. It is the process
of either encrypting or removing personally identifiable information from data sets. The entity
providing data should decide which information to keep for data to be useful and which to
anonymize or transform.
Step-5: Set up a secure data pipeline. A data pipeline is a series of data processing steps. It
enables a smooth, automated flow of data from one station to the next. It starts by defining
what, where, and how data is collected. It automates the processes involved in extracting,
transforming, combining, validating, and loading data for further analysis and visualization. Data
pipelines consist of three key elements: a source, a processing step or steps, and a destination.
42